
联合学习允许在严格的隐私约束下对机器学习模型进行协作训练,而联合文本到语音的目的是使用存储在本地设备中的少量音频训练样本来合成多个用户的自然语音。然而,联合文本到语音面临着如下挑战:每位发言人的训练样本很少,训练样本存储在用户的本地设备中,全局模型容易受到各种攻击。
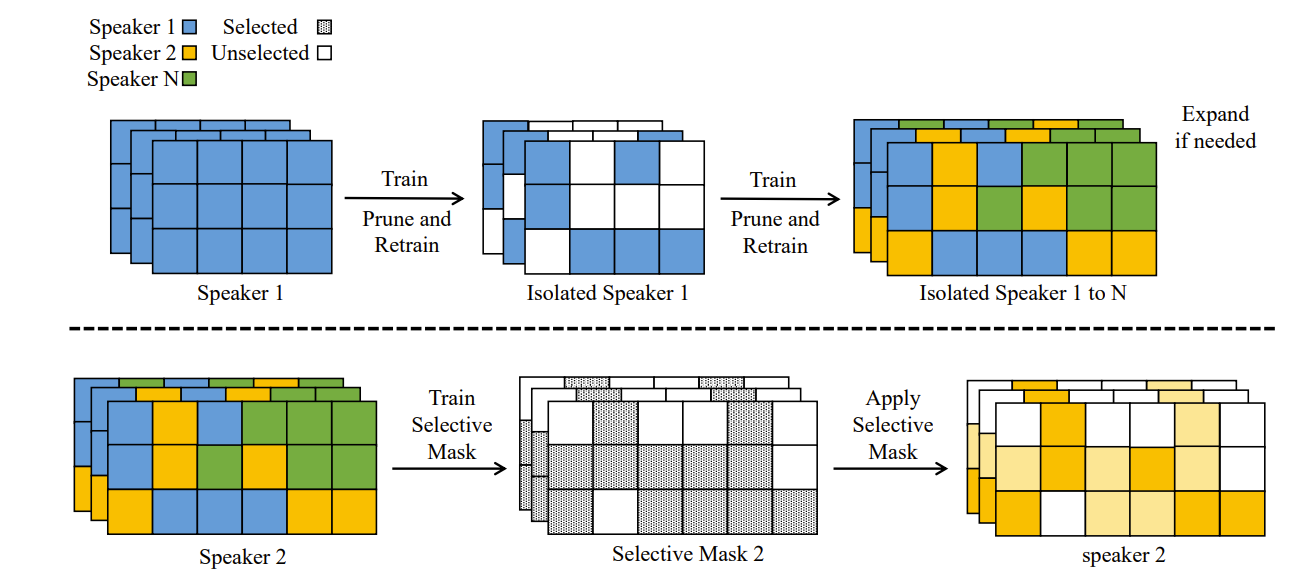
在本文中,赵洲博士(浙江大学上海高等研究院计算+AI实验室成员、浙江大学计算机科学与技术学院副教授)和他的团队提出了一个新颖的联合学习架构,即多发言人联合TTS系统(Fed-Speech),基于连续学习来解决上述挑战。具体来说,1)使用渐进式修剪掩码来分离参数,以保留发言人的语调;2)应用选择性掩码来有效地重用任务中的知识;3)引入私人发言人嵌入以维护用户隐私。
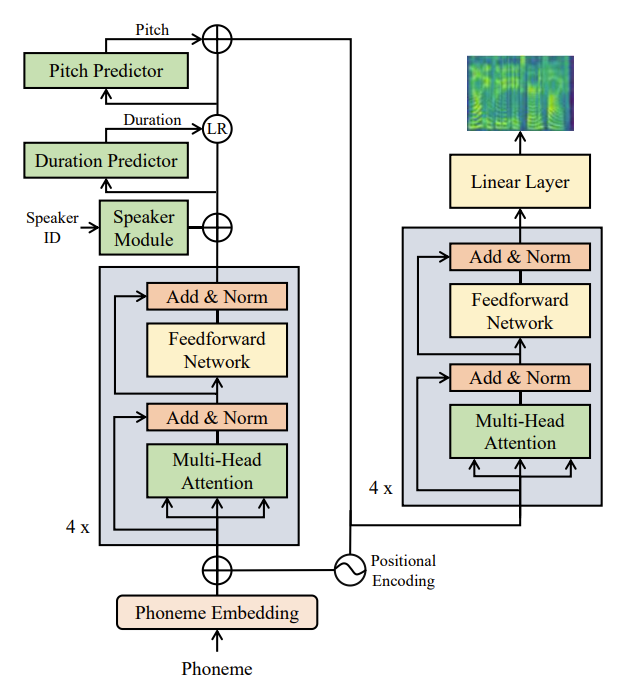
FedSpeech通过以下方法来解决上述挑战:
1)通过选择性掩码,FedSpeech可有效地从协作训练中获益,减少有限训练数据的影响;
2)逐渐修剪的掩码可隔离不同发言人参数,解决灾难性遗忘问题。因此,FedSpeech可避免了发言人的音调变化的问题。
3)引入私人发言人嵌入,连同上述两类掩码,以保护隐私,避免对发言人的攻击。
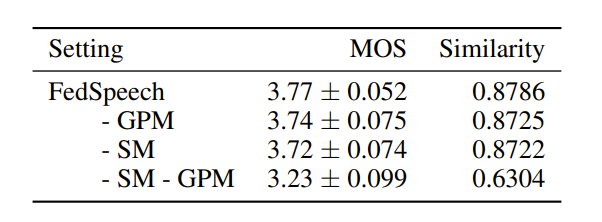
缩减VCTK数据集实验(每位发言人的训练集减少到四分之一,以模拟低资源的语言场景)表明,FedSpeech模型在语音质量、多任务训练方面几乎可达到现有各系统的最优性能,且在发言人相似性实验中明显优于其他系统。

在未来工作中,作者们将继续提高合成语音的质量,并提出新的掩蔽策略来压缩模型,加快训练。此外,将把FedSpeech应用于具有零点的多发言人设置,通过使用私人发言人模块来生成掩码。
文章详情请见[2110.07216v1] FedSpeech: Federated Text-to-Speech with Continual Learning (arxiv.org)。
