
近日,浙江大学上海高等研究院常务副院长吴飞教授、研究员王则可博士团队与阿里云智能CTO周靖人团队最新联合研究成果大规模图神经网络训练系统Legion被计算机系统国际会议USENIX ATC 23接收,该成果能够基于单服务器支持十亿级顶点规模的大图处理,对中小规模图的训练吞吐量显著高于现有最佳系统,性能提升可达4.32倍。
图神经网络(graph neural network, GNN)现已被广泛应用于电子商务平台的推荐、金融数据风险控制、化学药物合成、故障检测等领域。在这些应用中,用于训练GNN的图数据规模已经达到了十亿顶点、百亿边的级别。为了有效对大图训练,业界往往对大图中结点进行采样,并通过DGL、PyG或Graph-Learn等框架来进行训练。为此,现有训练框架会将图数据先完整装载进入CPU内存,然后CPU对图结点进行采样,将采样所得结点以mini batch形式传输至GPU进行信息传播和结点汇聚等训练操作。现有研究表明上述CPU和GPU之间数据传输已经成为系统性能提升的瓶颈。为此一些研究者提出了基于缓存的GNN系统来减少CPU-GPU数据传输。然而,团队在研究过程中发现,现有的基于缓存的GNN系统难以有效地处理大规模图数据,主要原因在于多GPU之间缓存扩展性较差以及采用了粗粒度管理策略对图拓扑结构进行存储。
为了高效进行大规模图神经网络计算,研究团队研发出了Legion系统。Legion能够充分发掘多GPU服务器之间潜力,加速大图训练。Legion充分考虑了GPU之间的互连特性,引入GPU互连感知的层级图分割机制,其与Legion的多GPU缓存机制协同工作,最大化多GPU内存利用率。同时, Legion为图结点特征和图拓扑结构依据热度感知设计了统一缓存,同时保证图结构拓扑和图结点特征的扩展性以及图采样性能。为了最大化系统计算的吞吐量,Legion引入了自动化缓存管理机制,可自动根据不同GPU互连、GPU内存容量、图数据集特性等信息,学习最优缓存方案。Legion让用户无需了解底层的硬件架构和图数据集复杂信息,就可高效训练大图。
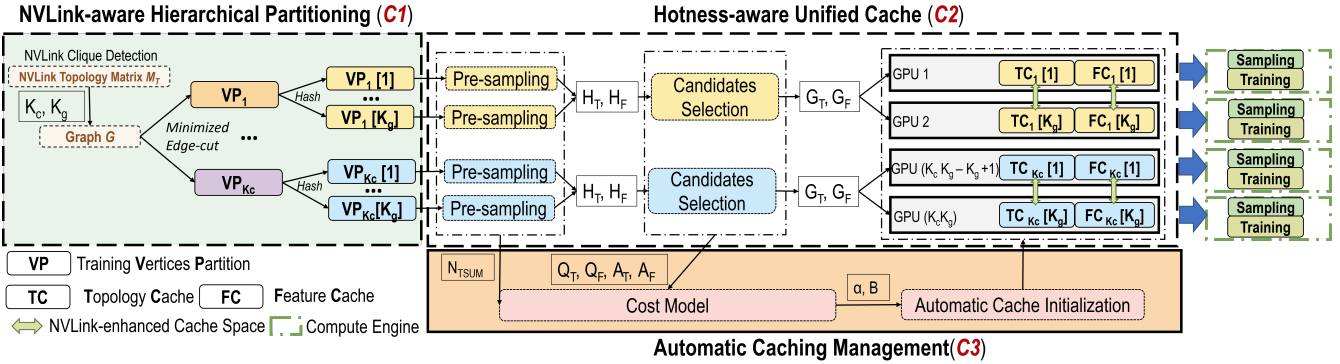
Legion计算架构
研究团队在不同规模的大型现实数据集上对Legion性能进行评估。结果表明Legion能够基于单服务器支持十亿级顶点规模的大图处理;同时,Legion对中小规模图的训练吞吐量显著高于现有最佳系统,性能提升可达4.32倍。
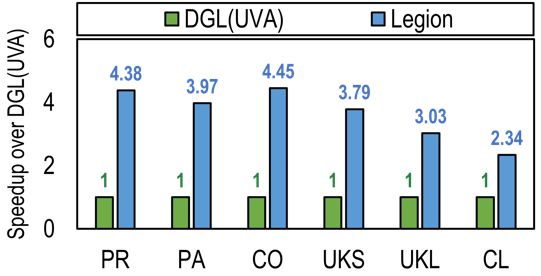
在A100机器上训练大图,其中UKL和CL为十亿级顶点大图

在V100机器上训练中小规模图,x表示内存溢出无法运行
本项目得到了上海人工智能创新中心科研项目和繁星科学基金等支持。
关于Legion项目
Legion项目是浙江大学和阿里巴巴集团协同开发的“大规模图神经网络模型端云协同计算平台”的重要部分之一。该项目相关研究成果此前还曾荣获2022年度高等学校科学研究优秀成果奖(科学技术)科技进步一等奖和中国电子学会2021年度科学技术奖(科技进步)一等奖。

大规模图神经网络模型端云协同异构计算平台
关于USENIX ATC
USENIX Annul Technical Conference (USENIX ATC),是计算机系统领域国际顶级学术会议,是CCF推荐A类会议。自1992年举办第一届USENIX ATC会议以来,至今已成功举办30多届,吸引了来自全球的名校及科技巨头投稿。USENIX ATC2023年共计投稿353篇,最终接收65篇,接收率为18.4%。
论文信息
题目:
Legion: Automatically Pushing the Envelope of Multi-GPU System for Billion-Scale GNN Training
作者:孙杰1,苏立2,史作成1,沈雯婷2,王则可1,王磊2,张杰1,李永2,于文渊2,周靖人2,吴飞1,3
浙江大学计算机学院1
阿里巴巴集团2
浙江大学上海高等研究院3
会议:
USENIX ATC 2023
论文链接:
https://jiesun233.github.io/Legion_Arxiv.pdf
