

浙江大学上海高等研究院常务副院长、浙江大学人工智能研究所所长吴飞教授在WAIC Circle AI年终论坛作主题演讲
随着人工智能技术的快速发展和广泛应用,当前正迎来一个科技驱动的新时代。2024新年伊始,生成式人工智能正在掀起新一轮浪潮,面对来势汹汹的颠覆与变革,我们应该如何理解生成式人工智能赋能内在机理?面对十倍增长的行业势能,如何将大模型基座变为垂直领域大模型,进而应用到行业创新中去?面对不断涌现的新技术,人工智能的未来又充满着哪些可能性?
2023年12月10日WAIC Circle AI年终论坛上,浙江大学上海高等研究院常务副院长、浙江大学人工智能研究所所长吴飞教授进行主题为《智海系列垂直领域大模型:LLM&Agent推动下从通到专》的分享,以下内容整理自吴飞教授演讲实录。
精彩观点
学科意义上人工智能的诞生有两个标志,第一是1955年8月31日在《关于举办达特茅斯人工智能夏季研讨会》项目建议书中首次出现了人工智能这一单词,第二是1956年美国达特茅斯夏季人工智能研讨会,都可以称之为人工智能的原点。
人工智能在短暂的70年发展中有着两落三起的曲折历程。我们非常幸运,正处于人工智能的第三次崛起阶段,产生式人工智能如今成为我们非常重要的武器,新一代人工智能的赋能应用正在到来。
在大数据、大模型、大算力的基础之上,Transformer以“共生则关联”的原则,实现了统计关联关系的挖掘,从而能够合成内容。
人工智能时代一直没有出现像Windows、安卓/iOS这样真正的操作系统——能够为用户提供信息系统入口/界面,同时可以管理计算资源并支撑应用开发。ChatGPT作为一种大语言模型,以自然语言交互形式,将各种apps以插件形式进行plugin,成为链接人类社会-信息空间-物理世界三元空间的流量入口。
人工智能还存在很多未解之谜,但真理是从相对走向绝对的渐进过程,所以我们知道的越来越多,对人工智能的了解就会越来越多。
人工智能的原点
人工智能在学科意义上的崛起,一种说法是在1955年8月31日。当时有四位专家John McCarthy(时任Dartmouth数学系助理教授,1971年度图灵奖获得者)、Marvin Lee Minsky(时任哈佛大学数学系和神经学系Junior Fellow,1969年度图灵奖获得者)、Claude Shannon(Bell Lab, 信息理论之父)、Nathaniel Rochester(IBM, 第一代通用计算机701主设计师)为了召开学术会议又苦于没有经费,于是向美国洛克菲勒基金会递交了一个项目申请书,项目申请书的题目叫做《达特茅斯夏季人工智能研究项目建议书》,在这份建议书中,“人工智能(Artificial Intelligence)”这一术语被首次使用,标志着人工智能这一研究开始登上人类历史舞台。所以可认为人工智能(Artificial Intelligence)在1955年8月31日首次登上人类历史舞台。

在这份建议书的首页,四位学者写道,“我们有一个猜想,学习的每一个方面和智能的大多数特点,原则上都可以被精确地描述出来,从而可以制造一台计算机来进行模拟。”所以,如果要把人类或生命体某一方面智能在机器上实现,首先要对智能产生过程清晰描述,才能用算法进行模拟,最后用编程语言刻画出来,进而在机器上实现,就像物理学家费曼曾讲过的一句话,“不可造也,未能知也“。
该项目建议书提交之后,基金会认为虽然申请书所提及研究内容难以让人明确领悟(difficult to grasp very clearly),但是鉴于这一研究具有长期挑战性,基金会愿意资助其申请经费的一半,即批准7500美元来支持这个研讨会,同时在回函中希望建议者不要介意基金会所表现出来的保守(over caution)。在这笔经费的支持下,1956年6月18日至8月初,一群科学家来到美国达特茅斯学院,围绕自动计算机、计算机编程、神经网络、计算的复杂度、智能算法的自我学习与提高、智能算法抽象能力、智能算法随机性与创造力等开展研究。

因此,学科意义上人工智能的诞生有两个标志,第一是1955年8月31日在《关于举办达特茅斯人工智能夏季研讨会》项目建议书中第一次使用人工智能这一单词,第二是1956年美国达特茅斯夏季人工智能研讨会,都可以称之为人工智能的原点。
为什么说GPT是人工智能的iPhone时刻?
其实,人工智能在短暂的70年发展中有着两落三起的曲折历程。我们非常幸运,正处于人工智能的第三次崛起阶段,产生式人工智能如今成为我们非常重要的赋能工具,新一代人工智能正为赋能每个人的工作和生活提供巨大能力。

英伟达创始人兼CEO黄仁勋等学者指出,随着ChatGPT为代表的生成式人工智能基座模型出现,我们已经进入“人工智能的iPhone时刻”,这一观点受到美国《财富》杂志、华尔街时报等媒体的广泛认可并转载。英国《自然》杂志列出的2023年度十大人物中,除了按惯例从全球的重大科学事件中评选出十位人物外,还列入生成式人工智能的产品ChatGPT。我们该如何去理解“人工智能的iPhone时刻”这句话呢?
2007年1月9日,乔布斯发布第一代iPhone苹果手机,把iPod、电话、移动互联网设备等进行有机整合,推动了移动互联网进入黄金发展年代,手机成为信息流量的主要的入口。那么在人工智能的时代,会不会出现新的信息流量入口呢?
可以认为,随着产生式人工智能基座模型的完善,其将所有的apps以plugin形式连接起来,每个人只要通过简单的自然语言交互,就能命令它完成所有任务,并且其能力在与人类交互中不断地增强,产生式人工智能基座模型将成为从互联网时代迈向人工智能时代的信息流量新入口。
ChatGPT这种产生式基座模型为什么有这么厉害的能力?我们先从GPT说起。GPT的全称叫做“产生式预训练Transformer(generative pre-training transformer)”。Transformer这一单词在人工智能领域内一般不作翻译,著名美国电影《变形金刚》的英文名字也叫做Transformer,所以,大家可以把Transformer想象成能够大变活人的非线性变换的魔方,如输入一段自然语言的描述,Transformer就可以把这段自然语言变换为其对应的答案或图片等。
Transformer是一种新的神经网络模型,其最重要的特点是引入了Attention(注意力机制)。什么是Attention?在自然语言处理领域,Attention可以理解为一个句子中每个单词要自己肩负起自己责任,对其所处上下文其他单词的频繁出现要特别“注意”,即通过注意力机制可以计算每个单词和其他单词在句子中出现的共生概率。
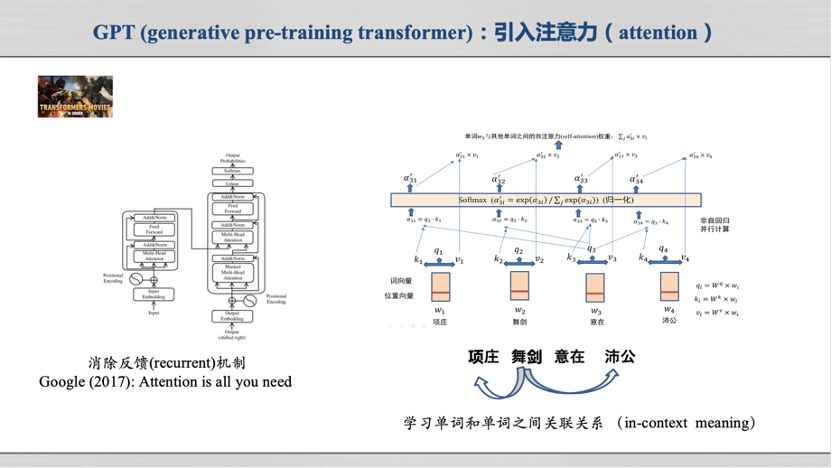
例如,Attention机制可以计算得到“项庄舞剑意在沛公”这句话中“项庄”、“舞剑”和“沛公”之间具有非常强的共生共现概率。于是,通过Attention技术,神经网络模型计算得到一句话、一个段落甚至一篇文章里面,每个单词与其他单词的共生共现概率。
一旦知道了任意一个单词和其他单词之间的共生概率,就可以如下完成内容合成任务了:先产生第一个单词,然后选择和第一个单词共生概率最强的单词作为第二个单词,接着选择和前面单词共生概率最强的单词,这样一个接着一个,一个句子就被合成出来了。所以,OpenAI的CEO Sam Altman曾经表示,“只要能够非常好的预测下一个Token,就能帮助人类创建AGI(通用人工智能)”。
Transformer有13亿参数,因此建立所有Token之间的概率关联并不是一件容易的事情。为此,OpenAI采用了训练Transformer的三板斧技术。
第一,完形填空下的自监督学习。
在训练时,人工智能模型会不断地在句子中“挖去”一个单词,根据剩下单词的上下文来填空这一被挖去单词,即预测最合适的“填空词”出现的概率。

比如,给出 “一辆列车缓慢行驶在崎岖的山路上”句子,如果把“缓慢”拿掉,让Transformer去预测在空白处上哪个单词才能更好地表达这句话的意思?如果填错了怎么办?
其实神经网络里面有个非常强大的参数优化算法,叫做误差后向传播。它会自动地计算模型预测的误差,于是每个参数就会自动根据这个误差来进行调整。在误差后向传播机制训练下, “缓慢”这一单词被模型计算所得出现概率最大。在互联网上采集下来亿级句子,任意去掉某个句子中一个单词,然后让模型完形填空。通过千锤百炼般训练,Transformer就能牢牢记住人类社会里面每个单词与其上下文单词之间的联系,于是,预测下一个Token的能力就形成了。也有人说,Transformer就是对人类信息空间的一种概率压缩,把单词与单词之间共同出现的上下文关联概率分析出来。
第二,提示学习和指令微调。
手工设计提示(prompt)和指令(instruction),让基座模型照葫芦画瓢,以便让人工智能模型说人话、做人事,实现大模型的有监督微调(supervised fine-tuning, SFT)。

我们人类自己写出 “这部电影很精彩,因为其剧情引人入胜”这样句子,然后把“引人入胜”去掉,让Transformer去预测缺失单词,如果模型能够把人类话语中精彩的单词预测出来,Transformer就达到了说人话的水平。做人事也是一样的思路,人类自己构造若干指令(如分析案情、预测刑期等)以及完成该指令所对应的回答,然后以“我教你学”方式教导模型完成该指令任务。在可预测下一个单词的神经网络基础之上,一般只需要15-25个例子可让transfomer完成类似任务,使得其能力不断迁移,这犹如中国古话“经师易得、人师难求”。
第三,人类反馈下强化学习。
谋定而后动,知止而有得。Transformer一旦训练成熟就可以开放给人类用户使用,当它回答出错或正确时候,我们人类分别给其反馈,让模型根据人类反馈进行纠正或提高。

上述过程可看出ChatGPT是数据、模型和算力三驾马车的有机组合首先,数据是燃料,无数据
AI。ChatGPT在训练中使用了45TB数据、近 1 万亿个单词(约1351万本牛津词典所包含单词数量)以及数十亿行源代码。据估计,全球高质量文本数据的总存量在5万亿token左右,人工智能算法可能在一个数量级内,耗尽世界上所有有用的语言训练数据供应。
再次,模型是引擎,数据越多模型运转更充分。ChatGPT包含了1750亿参数,将这些参数全部打印在A4纸张上,一张一张叠加后,叠加高度将超过上海中心大厦632米高度。
算力是加速器。ChatGPT的训练门槛是1万张英伟达V100芯片、约10亿人民币,模型训练算力开销是每秒运算一千万亿次,需运行3640天( 3640 PetaFLOPs per day )。
在大数据、大模型、大算力的基础之上,Transformer以“共生则关联”的原则,实现了统计关联关系的挖掘,从而能够合成内容。
人工智能时代一直没有出现像Windows、安卓/iOS这样真正的操作系统——能够为用户提供信息系统入口/界面,同时可以管理计算资源并支撑应用开发。ChatGPT作为一种大语言模型,以自然语言交互形式,将各种apps以插件形式进行plugin,成为链接人类社会-信息空间-物理世界三元空间的流量入口。
在此基础之上,我们看到,产生式人工智能推动机器学习研究范式发生了巨大的变化。以自然语言为例,以前进行自然语言研究之前,我们需要了解乔姆斯基文法、产生式规则等语言学知识,这个阶段研究自然语言是“语言为大”。后来,机器学习能力提升,我们不用去学语言知识,而是针对具体语言学任务(如句法分析、语义角色标注等)采集对应的数据来逐一训练模型,这个阶段是“计算为大、语言势微”。在大语言模型时代,我们需要通过语料数据驱动下模型的训练、指令/提示调优,让Transformer说人话、做人事,这个阶段叫做“计算为大、语言点金”。

有人说,大语言模型具有涌现的能力,该如何解释涌现之力呢?目前还没有科学上认同的解释。诺贝尔物理学奖得主、著名凝聚态物理学家菲利普·安德森于1972年在美国科学杂志发表了题为《多者异也》的论文,他指出“还原论假说从来都不意味着建构论假说”。即使我们了解了物理世界最基本单元夸克,我们仍然不能了解夸克所组成的生命机理或宇宙奥秘,只能说量变产生了质变,神经网络也是一样的,我们了解每个神经元运作的机理,但是把亿万个神经元组成1,750亿参数的GPT时,我们对其涌现的能力也无法做出科学的解释。
由通到专的大模型智能基座
在大语言模型涌现的背景之下,我们开始尝试用教科书级的语料来训练人工智能专业基座大模型 “智海-三乐”。
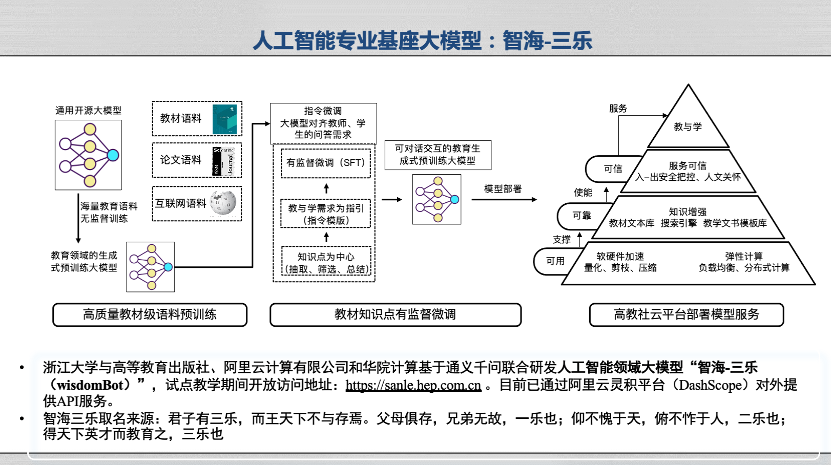
我们使用高等教育出版社出版的新一代人工智能系列教材中高质量语料对已有通用模型进行二次增量预训练,让其预测人工智能领域的下一个单词,然后通过教材中知识点构造提示/指令样例,让其说人工智能的人话、完成人工智能的人事,然后把其开放出来,让老师们和学生们在学习人工智能课程的时候使用。浙江大学、高教社、阿里云和华院计算研制的“智海-三乐”自2023年9月18日上线以来,面向浙江大学、同济大学、哈尔滨工业大学、武汉大学、吉林大学、辽宁大学、大连理工大学、华中科技大学、北京师范大学等14所高校进行教育部计算机领域本科教育教学改革试点工作计划(101计划)核心课程《人工智能引论》教学工作,服务530名学生,进行了上万次对话服务。
此外,浙江大学还面向青少年群体推出人工智能科普读物《走进人工智能》、与高等教育出版社共同打造原创人工智能前沿科普有声通识数字栏目《走进人工智能》,让青少年在课程中使用大模型的同时,提升对人工智能的学习兴趣与科学素养。随着人工智能学科建设的完备、专业模型的不断普及,人工智能的普及教育将会迎来全新的发展阶段,大模型在本科教育的垂直领域应用也将具备极大的发展潜力。

在司法领域,浙江大学、阿里云和华院计算联合开发了一个司法领域基座模型“智海-录问”,在这个过程中我们应用司法领域的数据对智海-录问进行锤炼。
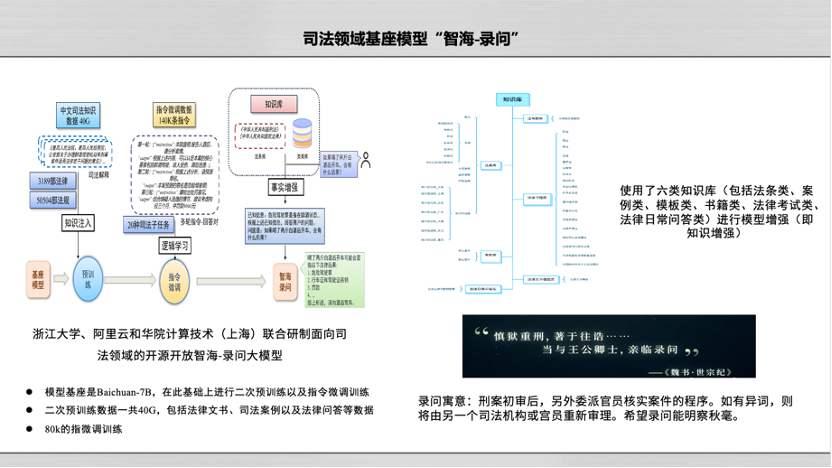
“智海-录问”于2023年9月18日发布,为了让智海-录问克服人工智能幻觉这一不足,我们输入了40G中文司法知识数据,进行了140K指令微调,通过法条库和案例库不断进行事实增强,使其具备司法推理的能力。目前,“智海-录问”已在GitHub上开源,同时在阿里云魔搭社区进行开放,也在法学教育与实践中开始应用,收到良好的反馈。
最近,AI Agent非常火爆,我们基于大语言模型和Agent做了一个基于数据评估Agent的开源项目“InfiAgent-Eval”。

如果你上传“人均生产总值”和“预期寿命”的数据,并提问二者是否存在线性相关,大语言模型会自动生成代码,计算其相关系数,结果显示,线性相关的序数是0.67,因此,这两个因素不具有线性相关的关系。
基于此,我们发现,大语言模型具有很强的感知、推理、决策和预测的能力,如果把大语言模型当成一个大脑,向它提问,让其在分析理解问题基础上,调用其它工具或者模型加以辅助完成问题,就能让大语言模型发挥知行合一的能力。未来,AI Agent将具有巨大的发展潜力。
人工智能之不能的若干原因
一、数据偏差
数据驱动是人工智能第三次崛起的原因,如果数据有偏差怎么办?这就是所谓的幸存者偏差,是机器学习中要克服的一大难点。
例如,二战期间,为了加强对战机的防护,英美军方调查了返航飞机上弹痕的分布,发现返航幸存飞机中机翼上弹痕最多、发动机引擎上几乎没有弹孔,因此军方建议要加强机翼的防护。但哥伦比亚的统计学家沃德教授说,所有机尾油箱中弹的飞机,你再也看不见了,因此要加强对机尾油箱的保护。这就好比在战地医院,英勇士兵因为手部或腿部中弹在疗伤,很少见到头部中弹士兵在疗伤。我们总不能建议把保护士兵头部的钢盔材料削减一半去保护士兵的腿部和手部,这样就犯下了常识性错误,这一错误对机器而言是幸存者偏差(即数据偏差)所造成。

二、明朝数据“光速”入清廷
洪武十四年(1381年),明朝在户帖制度基础上建立了黄册制度。黄册以户为单位,详细登载乡贯、姓名、年龄、丁口、田宅、资产等信息,并按从事职业,划定民、军、匠三大类户籍。黄册十年一大造,实际上就是十年进行一次人口普查和财产调查。明代黄册是明代国家为核实户口、征调赋役而制成的户口版籍,成为国家运行的根本。
但是,从十五世纪中叶起,明朝各地的土豪劣绅开始用黄册造假的方式来逃避赋役,原本国家可以收取赋税的土地,常被各级高官豪强巧立名目并掉。黄册中信息造假已经病入膏肓。公元1645年,清军攻占南京后,对存放于玄武湖的黄册库很感兴趣,打开黄册库房看后,没想到黄册上所记录人口、田产等信息已经编排到了崇祯二十四年,而明朝末代皇帝朱由检早于崇祯十七年留下“皆诸臣之误朕也”怨恨,在煤山自缢而死,黄册记录信息已“人为超前”了七年之久。原来那些造假成习惯的明朝官员,却已经把“崇祯二十四年”的黄册都造好,就等着到时候交上去凑数!

三、知其然且知其所以然
加州大学伯克利分校统计系教授彼得·毕克(Peter J .Bickel)在美国《科学》杂志发表了一篇有趣论文来讨论“伯克利分校录取新生时性别歧视”的困惑。在文章中,彼得教授统计了当年度所录取学生中男生和女生人数后,发现当年度男生录取率为44%,远高于女生录取率35%。然而,如果单独统计每个院系的录取情况,惊奇地发现,对于每个院系而言,男生录取率和女生录取率相差无几,甚至对伯克利六个最大院系分别统计男生和女生录取率,竟然有四个院系女生录取率大于男生录取率。
也就是说,将所有新生按照院系分组后,统计得到男生和女生的录取率,与不按照院系分组统计男生和女生的录取率结果正好相反。这就是著名的辛普森悖论(Simpson’s paradox)。辛普森悖论反映了总体数据集上成立的某种关系却在分组数据集合中“反其道而行之”这一怪异现象。
在伯克利男生和女生录取率这个案例中,产生悖论原因在于女生更愿意申请那些竞争压力很大的院系(比如英语系),但是男生却更愿意申请那些相对容易进的院系(比如工程学系)。在分析伯克利分校录取率时,不应该只看到男生和女生这个性别因素,还应该知晓“专业选择”这一因素会对新生录取产生作用。
“横看成岭侧成峰”,同样的数据会存在千万种解读。但是,与“历史不是任人打扮的小姑娘”一样,数据也不是任人打扮的小姑娘。辛普森悖论的重要性在于告诉如下道理:很多时候我们看到的数据并非反映现象全貌的数据,如果忽略产生数据的“潜在变量”,可能会改变已有结论,而我们常常却一无所知。比如伯克利招生录取中专业选择就是一个潜在变量。从观测结果中寻找引发结果的原因,“知其然且知其所以然”,由果溯因,就是因果推理 。

德国大数学家希尔伯特说过这样一句话,“我们必须知道,我们必将知道”。虽然我们现在还不知道为什么大模型能有涌现的能力?为什么能够完成万千任务?但我们终于清楚了单词与单词之间的共现规律、监督微调的步骤、人在回路的强化学习过程。人工智能还存在很多未解之谜,但真理是从相对走向绝对的渐进过程,所以我们知道的越来越多,对人工智能的了解就会越来越多。
本报告部分素材来自:
数字有声读物《走进人工智能》,高等教育电子音像出版社有限公司(入选中国音像与数字出版协会“2023年数字阅读推荐作品”)
科普读物《走进人工智能》,高等教育出版社出版
