
Starting from BERT, large-scale pre-trained models have become the focus of the natural language processing (NLP) research community. Recent years have witnessed substantial work on large-scale pretraining in NLP. One trend is to improve model capacities such as RoBERTa, GPT2, and GPT3, Another trend is to design pretraining objectives such as masked language model and masked span generation.
However, many up-to-date pre-trained models are designed for English: the known high-quality corpora are in English (the internet and book corpora); the model architecture is designed for English (missing Chinese glyph and pinyin information).
Prominent features of Chinese characters are twofold: one is the character glyph and the other is the pinyin. Chinese is a logographic language. Chinese character glyphs encode rich semantic information. For example, three water dots in “rivers and lakes”indicate that they are related to water.
As for pronunciation, the pinyin of Chinese characters handles the highly prevalent heteronym phenomenon in Chinese. The same character has different pronunciations with different meanings. For example, there are two pronunciations of the word music, yuè and lè.
The first is a noun representing music, while the second is an adjective denoting happy. Previous neural network models cannot specify the meaning between music and happiness given the vocab index of 乐. This shows the necessity of treating the pronunciation as additional model input.
In this paper, Dr. Jiwei Li, Dr. Fei Wu and their colleagues propose ChineseBERT by integrating the morphological and pinyin information of Chinese characters into the large-scale pre-trained models. The glyph vector of a Chinese character is obtained by combining different fonts (i.e., FangSong, XingKai and LiShu) and the pinyin vector is obtained by encoding a sequence of romanized pinyin characters (using the opensourced pypinyin package). The fusion layer in the model combines the glyph vector, the pinyin vector, and the word index vector to form a fusion vector. Then the fusion vector is forwarded to the upper layer of the model. The authors trained the model using the whole word masking strategy and the character masking strategy for enhancing the connection between Chinese characters, character shapes, pronunciation, and context.
ChineseBERT achieves new state-of-the-art (SOTA) performances on machine reading comprehension, natural language inference, text classification, sentence pair matching, named entity recognition, and word disambiguation tasks.
In the analysis experiment,, ChineseBERT achieves better results with less training data. This phenomenon shows the glyph and pinyin embeddings serve as strong regularization over text semantics.
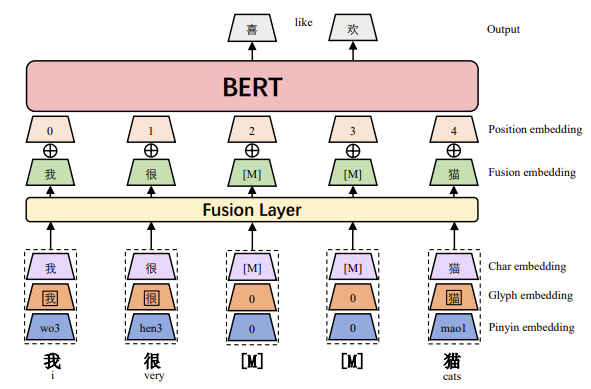
The main improvement is the fusion layer at the bottom of the model, which merges glyph, pinyin, and char-id embeddings into one fusion embedding. The fusion embedding is then added with the position embedding, which is fed as input to the model.

The glyphs are characterized by using images of Chinese characters in different fonts. Each image has a size of 24*24. The glyph embedding is obtained by concatenating images from thress fonts (i.e. song imitation, running script, and clerical script) and then passing them to a fully-connected layer.
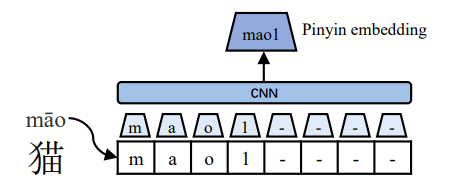
Pinyin embedding is constructed by firstly using pypinyin to convert the pinyin of each Chinese character into a sequence of romanized characters, with one of four diacritics denoting tones.
For example, the pinyin string of Chinese character 猫 is mao1. As for polyphonic characters like 乐, pypinyin can identify the correct pronunciation given the context. After that, a CNN with width 2 and the maximum pooling operation encode the sequence romanized characters for getting the pinyin embedding.
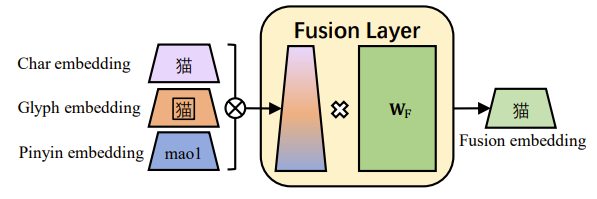
The character embedding, glyph embedding, and pinyin embedding of a Chinese character are merged, and then pass to a fully concatenated layer for obtaining the fusion embedding.
The fusion embedding is added to the position embedding. Then the vector is forwarded to the upper layer of the model. The model is pre-trained using the masked language model with Whole Word Masking (WWM) and Char Masking (CM) strategies .
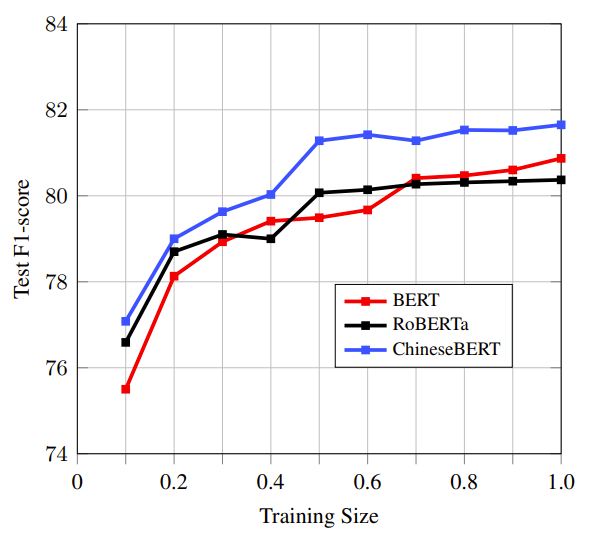
Pretrained on large-scale unlabeled Chinese corpus, the proposed ChineseBERT model yields a significant performance boost over baseline models with fewer training examples. The proposed model achieves new SOTA performances on a wide range of Chinese NLP tasks,including machine reading comprehension, natural language inference, text classification, sentence pair matching, and competitive performances in named entity recognition and Chinese word segmentation.
This work was accepted to ACL-2021 main and is available at (PDF) ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information (researchgate.net) The code and pretrained model checkpoints can be accessed at https://github.com/ShannonAI/ChineseBert.
About Professor Jiwei Li
Jiwei Li received his PhD degree from the Computer Science Department at Stanford University. He worked with Pro.f Dan Jurafsky at Stanford and Eduard Hovy at CMU.His main research areas involve natural language processing, deep learning and bioinformatics. He was awarded Global 35 Innovators under 35 from the MIT Technology Review and Forbes 30 under 30.
About Professor Fei Wu
Fei Wu received his B.Sc., M.Sc. and Ph.D. degrees in computer science from Lanzhou University, University of Macau and Zhejiang University in 1996, 1999 and 2002 respectively. From October, 2009 to August 2010, Fei Wu was a visiting scholar at Prof. Bin Yu's group, University of California, Berkeley. Currently, He is a Qiushi distinguished professor of Zhejiang University at the college of computer science. He is the vice-dean of college of computer science, and the director of Institute of Artificial Intelligence of Zhejiang University.
He is currently the Associate Editor of Multimedia System, the editorial members of Frontiers of Information Technology & Electronic Engineering. He has won various honors such as the Award of National Science Fund for Distinguished Young Scholars of China (2016).
His research interests mainly include Artificial Intelligence, Multimedia Analysis and Retrieval and Machine Learning.
About SIAS
Shanghai Institute for Advanced Study of Zhejiang University (SIAS) is a jointly launched new institution of research and development by Shanghai Municipal Government and Zhejiang University in June, 2020. The platform represents an intersection of technology and economic development, serving as a market leading trail blazer to cultivate a novel community for innovation amongst enterprises.
SIAS is seeking top talents working on the frontiers of computational sciences who can envision and actualize a research program that will bring out new solutions to areas include, but not limited to, Artificial Intelligence, Computational Biology, Computational Engineering and Fintech.