
Federated learning enables collaborative training of machine learning models under strict privacy restrictions and federated text-to-speech aims to synthesize natural speech of multiple users with a few audio training samples stored in their devices locally. However, federated text-to-speech faces several challenges: very few training samples from each speaker are available, training samples are all stored in local device of each user, and global model is vulnerable to various attacks.
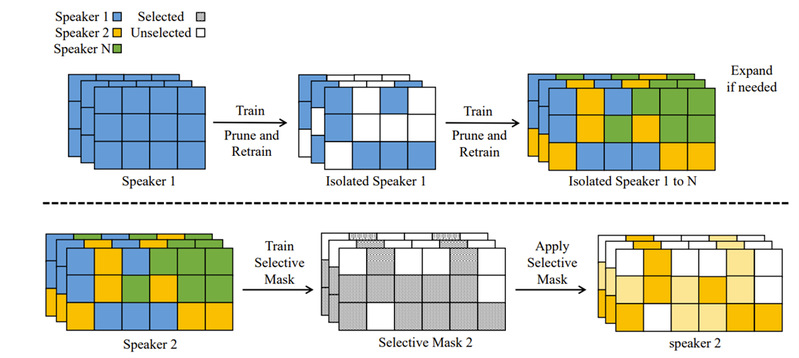
In this paper, Dr Zhou Zhao and his group proposed a novel federated learning architecture, called federated multi-speaker text-to-speech TTS system Fed-Speech, based on continual learning approaches to overcome the difficulties above. Specifically, 1) they used gradual pruning masks to isolate parameters for preserving speakers’ tones; 2) they applied selective masks for effectively reusing knowledge from tasks; 3) a private speaker embedding is introduced to keep users’ privacy.
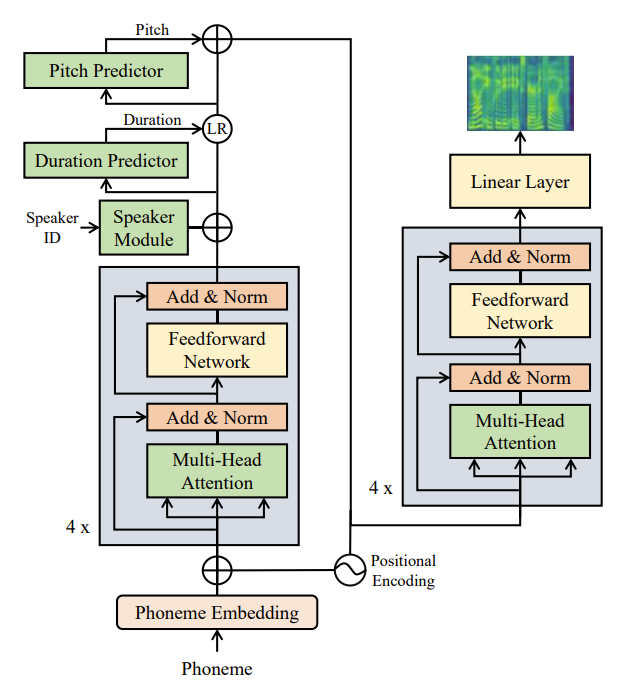
FedSpeech could address the challenges mentioned above as follows:
1) With selective masks, FedSpeech can effectively benefit from collaborative training to lessen the influence of limited training data;
2) Gradual pruning masks isolate the parameters of different speakers to overcome catastrophic forgetting issues. Thus, FedSpeech avoids the issue of tone changes for all speakers;
3) The private speaker embedding is introduced coupled with two types of masks above to preserve the privacy and avoid various attacks for speakers.
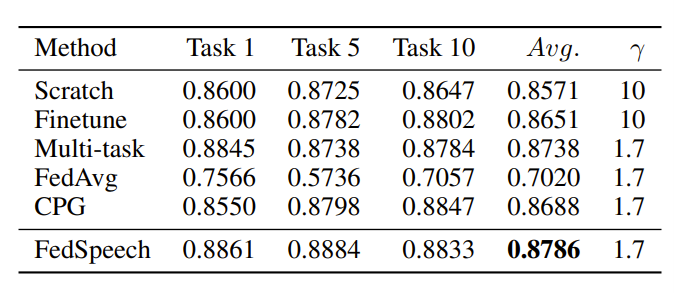
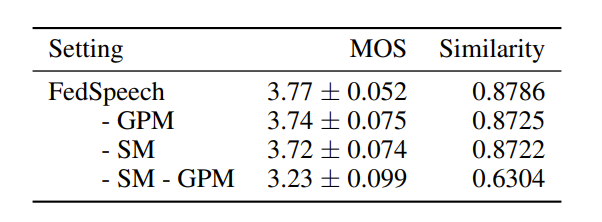
Experiments on a reduced VCTK dataset (the training set is reduced to a quarter for each speaker to simulate low-resource language scenarios) demonstrate that the proposed FedSpeech can nearly match the upper bound, multi-task training in terms of speech quality, and even significantly outperforms all systems in speaker similarity experiments.
For future work, the authors will continue to improve the quality of the synthesized speech and propose a new mask strategy to compress the model and speed up training. Besides, they will also apply FedSpeech to zero-shot multi-speaker settings by using the private speaker module to generate our proposed masks.
To access the original article, please visit [2110.07216v1] FedSpeech: Federated Text-to-Speech with Continual Learning (arxiv.org).
About Professor Zhao:
Zhou Zhao received the B.S. and Ph.D. degrees in computer science from the Hong Kong University of Science and Technology Hong Kong China in 2010 and 2015, respectively. He is currently an Associate Professor at the College of Computer Science,Zhejiang University in Hangzhou, China. His research interests include machine learning, data mining, multi-module learning, computer vision and natural language processing. Dr Zhao has published with NIPS, ICLR, ICML, CVPR and ACM MM conferences.
About SIAS:
Shanghai Institute for Advanced Study of Zhejiang University(SIAS) is a jointly launched new institution of research and development by Shanghai Municipal Government and Zhejiang University in June, 2020. The platform represents an intersection of technology and economic development, serving as a market leading trail blazer to cultivate a novel community for innovation amongst enterprises.
SIAS is seeking top talents working on the frontiers of computational sciences who can envision and actualize a research program that will bring out new solutions to areas include, but not limited to, Artificial Intelligence, Computational Biology, Computational Engineering and Fintech.