
Arbitrary-shaped scene text detection aims to accurately locate tight text regions of arbitrary shapes from natural scene images. The main challenge lies in the complex appearance of texts, such as arbitrary shapes, skewed viewpoints, and large aspect ratios. Due to the cluttered distribution and highly homogeneous texture of texts, separating geographically close instances from segmentation maps is a nontrivial problem for segmentation-based text detection methods.
To address this, Professor Xi Li and his team from Zhejiang University proposed a segmentation-based method that directly models two fuzzy semantic categories, text and separatrix, and uses an end-to-end framework for multi-label categorization and reliability prediction. The work was published as ‘Fuzzy Semantics for Arbitrary-Shaped Scene Text Detection’ in IEEE Transactions of Image Processing.
The authors introduced segmentation-based methods as frequently used for scene text detection and explored two types of fuzzy semantics, text and separatrix, in a multi-branch segmentation framework. They generated textness maps by solving the competition between text and separatrix with the help of reliability analysis. By focusing on text regions and instance separatrixes, they addressed the issue of unclear text boundaries in images. They proposed a redundancy removal strategy that directly discovers separatrixes between adjacent text instances and excludes separatrix pixels from text regions on the segmentation map. They introduced reliability analysis based on the distance to the nearest semantic boundary, applied during both training and inference stages, adjusting pixel weights according to their reliability. This strategy provided a more intuitive and flexible approach compared to directly segmenting separatrix-excluded text areas.
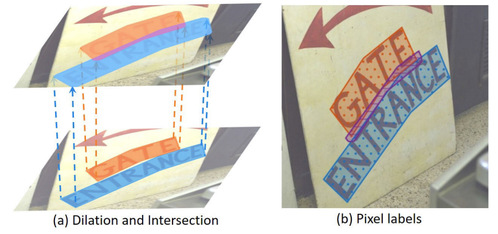
Figure 1. Illustration of pixel labeling. In (a), instances are dilated and intersect with each other at separatrix area. (b) shows the pixel labeling results: dotted areas represent text regions while hatched area represents separatrix.
The authors developed an end-to-end segmentation framework consisting of feature extraction, feature fusion, and multi-branch joint optimization. ResNet50 and FPN were employed for feature extraction, while the feature fusion strategy followed SOLOv2. Text segmentation, text reliability regression, separatrix segmentation, and separatrix reliability regression were conducted simultaneously using parallel branches. During the inference stage, four score maps were predicted and then fused to generate the final textness map. The method used joint optimization among the four tasks, employing cross-image normalized focal loss with the guidance of reliability in the segmentation tasks.
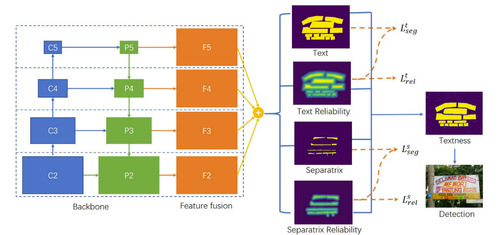
Figure 2. Overall architecture of our framework. Four parallel branches conduct text segmentation, text reliability regression, separatrix segmentation and separatrix reliability regression, respectively. Orange dotted lines indicate training strategy, while blue lines depict the inference pipeline
The framework was evaluated on three standard arbitrary-shaped scene text detection datasets: SCUT-CTW1500, Total-Text, and ICDAR-ArT. A series of ablation studies demonstrated the effectiveness of fuzzy semantics exploration, reliability analysis, and cross-image normalized focal loss in arbitrary-shaped scene text detection. The results showed significant improvements in F-measure when incorporating separatrix segmentation, reliability analysis, and the proposed cross-image normalized focal loss.

Table 1. Ablation study on CSCUT-CTW 1500 and TotalText
The method demonstrated effectiveness and efficiency in detecting curved texts, multi-oriented texts, and arbitrary-shaped multi-lingual texts across various benchmark datasets (TotalText, SCUT-CTW1500, ICDAR-ArT, MSRA-TD500, and ICDAR2015). It outperformed several existing methods such as PSENet, CSE, PAN, and DB in various scenarios and maintained high running speeds, with ResNet50 and ResNet18 versions achieving approximately 25FPS and 35FPS, respectively. The performance trade-off with respect to input sizes was studied, and the model maintained satisfactory performance at various input sizes. Overall, the method proved to be both effective and efficient, surpassing state-of-the-art methods in text detection.

Figure 3. Outputs demonstration on TotalText. Rows from top to bottom are text segmentation maps, separatrix segmentation maps, text reliability predictions, separatrix reliability predictions, fused textness maps, initial detections extracted from text segmentation maps and final detections extracted from textness maps. The merged instances in the initial detections are visualized by a single color area, while in the final detections the instances are separated and visualized by different colors
To access the full article, please refer to https://ieeexplore.ieee.org/document/9870672.
About Professor Li
Dr Xi Li is a Professor of College of Computer Science and Technology at Zhejiang University, and the Deputy Dean of Shanghai Institute for Advanced Study of Zhejiang University (SIAS).
He is an IET Fellow and an IEEE Senior Member, and the winner of Zhejiang Provincial Science Foundation for Outstanding Young Scholars. Dr. Li was appointed as a distinguished expert of the Zhejiang Province government. He also served as a council member of the China Image and Graphics Society.
Professor Li obtains a wealth of academic experience in serving as program committee members of top conferences (e.g., NIPS, ICML, CVPR, ICCV) or reviewers of premier journals (e.g., IEEE TPAMI, IJCV, IEEE TIP). Besides, he made several invited talks at well-known conferences (i.e., RACV 2016, ICSW 2017, ICDS2017, IEEE FMT 2018).
He focuses his research on the AI fields of computer vision and machine learning, and has published approximately 150 top conferences and leading journal papers with about 4600 Google Scholar citations. He devoted his efforts to enabling many academic roles in conference organization (e.g., PRCV2019 AC, ICPR 2018 AC, IJCAI 2019 SPC, and ICCV 2019 AC, CVPR 2020AC, ICPR 2020 AC) and journal editorial management (e.g., AEs of IEEETNNLS, IEEE TCSVT, Neurocomputing, and Neural Processing Letters). He has won two Best International Conference Paper Awards (including ACCV2010 and DICTA 2012), an ICIP 2015 Top 10% Conference Paper Award, and an ACML 2017 Best Student Paper Award. In addition, he won two China Natural Science and Technology Awards (including first-class and second-class prizes) and a Chinese Patent Excellence Award.
About SIAS
Shanghai Institute for Advanced Study of Zhejiang University (SIAS) is a jointly launched new institution of research and development by Shanghai Municipal Government and Zhejiang University in June, 2020. The platform represents an intersection of technology and economic development, serving as a market leading trail blazer to cultivate a novel community for innovation amongst enterprises.
SIAS is seeking top talents working on the frontiers of computational sciences who can envision and actualize a research program that will bring out new solutions to areas include, but not limited to, Artificial Intelligence, Computational Biology, Computational Engineering and Fintech.