
Knowledge amalgamation (KA) is a novel deep model reusing task aiming to transfer knowledge from several well-trained teachers to a multi-talented and compact student. Currently, most of these approaches are tailored for convolutional neural networks (CNNs). However, there is a tendency that Transformers, with a completely different architecture, are starting to challenge the domination of CNNs in many computer vision tasks. Nevertheless, directly applying the previous KA methods to Transformers leads to severe performance degradation.
Recently, Professor Mingli Song and his team explored a more effective KA scheme for Transformer-based object detection models, and the work was published as ‘Knowledge Amalgamation for Object Detection with Transformers’ in IEEE Transactions on Image Processing.
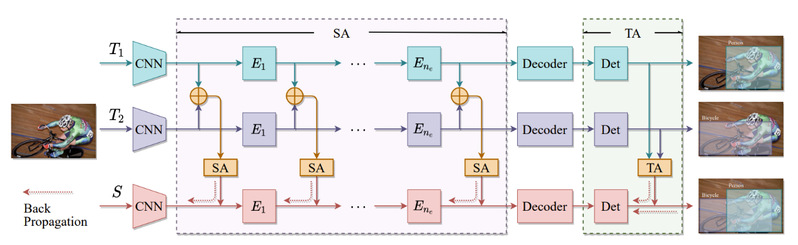
The overall workflow of our proposed knowledge amalgamation method for transformer-based object detectors is shown in the two-teacher case.
Specifically, considering the architecture characteristics of Transformers, the authors proposed to dissolve the KA into two aspects: sequence-level amalgamation (SA) and task-level amalgamation (TA). The method aimed to transfer knowledge from several well-trained teachers to one compact yet multi-talented student, which was explicitly capable of detecting all the categories taught by given teachers. Such method was composed of two separate components. (1) Sequence-level amalgamation (SA): for the CNN backbone and all encoder layers, the intermediate sequence of the student was supervised by concatenated (and compressed) outputs of all corresponding teacher sequences; (2) Task-level amalgamation (TA): the student learns heterogenous detection tasks by mimicking the soft targets predicted by teachers. The gradient flows were shown as the dotted lines in the figure above from KA modules and the ground truth supervision.
In particular, a hint is generated within the sequence-level amalgamation by concatenating teacher sequences instead of redundantly aggregating them to a fixed-size one as previous KA approaches. Besides, the student sequences were supervised by partial teacher hints, compressed based on various sequence compression strategies, i.e., index set Pslim. However, the authors have kept the integrity of vision tokens (they were either preserved or discarded) to avoid introducing noise as the SAG approach. The student learnt heterogeneous detection tasks through soft targets with efficiency in the task-level amalgamation.
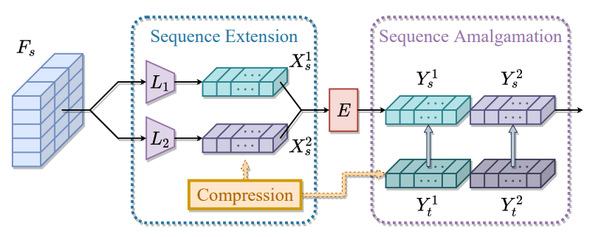
Illustration of sequence extension and sequence-level amalgamation for the student model.

Illustration of different sequence compression methods.
Extensive experiments on widely-used object detection datasets PASCAL VOC and COCO had unfolded that the sequence-level amalgamation significantly boosts the performance of students, while the previous methods impaired the students. Particularly, the authors discovered that the student significantly outperformed the baseline setting (increases about 5 percentage points on VOC and 4 percentage points on COCO), and the AP learning curves compared with the baseline settings on both VOC and COCO datasets were shown respectively in the figure below.
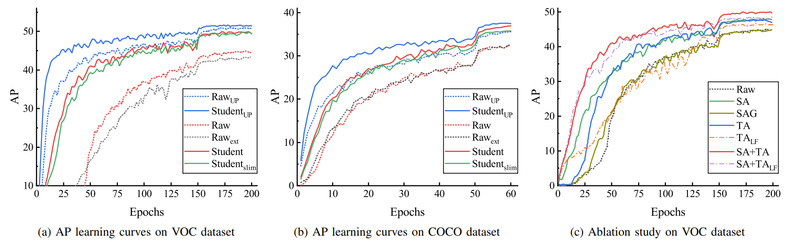
Average precision (COCO style) learning curves of our proposed method and baseline settings evaluated on PASCAL VOC and COCO datasets.
Moreover, the authors compared the proposed SA method with the sequence aggregation approach widely adopted in previous KA methods for the CNNs, and found that the transformer-based students exceled in learning amalgamated knowledge, as they have mastered heterogeneous detection tasks rapidly and achieved superior or at least comparable performance to those of the teachers in their specializations.
The work could be accessed at https://ieeexplore.ieee.org/document/10091778.
About Professor Song
Mingli Song is currently a jointly appointed professor in College of Computer Science and Technology and SIAS, Zhejiang University. He is leading Vision Intelligence and Pattern Analysis (VIPA) Group of ZJU. He received his Ph. D degree in Computer Science and Technology from College of Computer Science, Zhejiang University, and B. Eng. Degree from Northwestern Polytechnical University. He was awarded Microsoft Research Fellowship in 2004.
His research interests mainly include Computational Vision, Pattern Recognition, Machine Learning, Embedded Machine Vision and Visual Interaction. He has authored and co-authored more than 120 scientific articles at top venues including IEEE T-PAMI, IEEE T-IP, T-MM, T-SMCB, Information Sciences, Pattern Recognition, CVPR, ECCV and ACM MM.
He is an associate editor of Information Sciences, Neurocomputing and an editorial advisory board member of Recent Patent on Signal Processing. He has served with more than 10 major international conferences including ICDM, ACM Multimedia, ICIP, ICASSP, ICME, PCM, PSIVT and CAIP, and more than 10 prestigious international journals including T-IP, T-VCG, T-KDE, T-MM, T-CSVT, and TSMCB. He is a Senior Member of IEEE, and Professional Member of ACM.
About SIAS
Shanghai Institute for Advanced Study of Zhejiang University (SIAS) is a jointly launched new institution of research and development by Shanghai Municipal Government and Zhejiang University in June, 2020. The platform represents an intersection of technology and economic development, serving as a market leading trail blazer to cultivate a novel community for innovation amongst enterprises.
SIAS is seeking top talents working on the frontiers of computational sciences who can envision and actualize a research program that will bring out new solutions to areas include, but not limited to, Artificial Intelligence, Computational Biology, Computational Engineering and Fintech.