
In recent years, the convolutional segmentation network has achieved remarkable performance in the computer vision area. However, training a practicable segmentation network is time- and resource-consuming.
Focusing on the semantic image segmentation task, Professor Mingli Song and his colleagues attempted to disassemble a convolutional segmentation network into category-aware convolution kernels and achieved customizable tasks without additional training by utilizing those kernels. The core of disassembling convolutional segmentation networks is how to identify the relevant convolution kernels for a specific category. According to the encoder-decoder network architecture, the disassembling framework, named Disassembler, was devised to be composed of the forward channel-wise activation attribution and backward gradient attribution. In the forward channel-wise activation attribution process, for each image, the activation values of each feature map in the high-confidence mask area were summed into category-aware probability vectors. In the backward gradient attribution process, the positive gradients w.r.t. each feature map in the high-confidence mask area were summed into a relative coefficient vector for each category. With the cooperation of two vectors, the Disassembler could effectively disassemble category-aware convolution kernels.
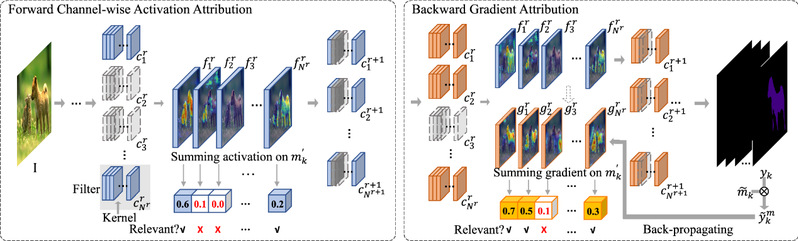
The framework of the Disassembler contains the forward channel-wise activation attribution and the backward gradient attribution.
In this work, Professor Mingli Song and colleagues proposed the first convolutional segmentation network disassembling framework, which could identify category-aware components maintaining original performance without additional training to achieve category-customizable tasks by combining forward and backward attribution together. They further summarized a novel finding that the same/different categories had similar/disparate activation responses, which could be used for further research on semantic segmentation networks. Based on the above finding, the forward channel-wise activation attribution was devised to identify category-aware convolution kernels in the segmentation network. The backward gradient attribution adopted in the image classification task was extended to the more complicated semantic segmentation by multiplying intermediate features with high-confidence masks, which could effectively filter out redundant convolution kernels sought by the forward activation attribution.
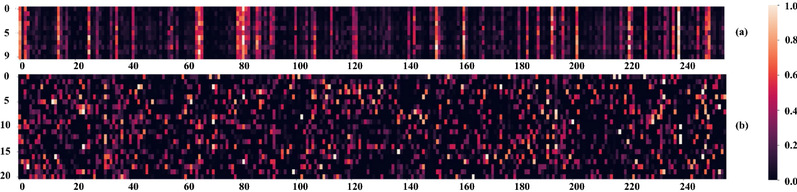
The visualization of convolution filters (attributed with the proposed backward gradient attribution) for samples of the same category (a) and different categories (b) in the penultimate layer of DeepLabV3 (ResNet-50) trained on the MSCOCO (Lin et al., 2014) dataset. The y-axis of (a) and (b) is the image id and the category id, respectively, and the x-axis index refers to different channels in the layer. The samples of the same category and different categories have similar and diverging activation patterns
Extensive experiments demonstrated that the proposed Disassembler could accomplish the category-customizable task without additional training. The disassembled category-aware sub-network achieved comparable performance without any finetuning and would outperform existing state-of-the-art methods with one epoch of finetuning.
The work was published as ‘Disassembling Convolutional Segmentation Network’ in International Journal of Computer Vision. To learn more about the review, please visit https://link.springer.com/article/10.1007/s11263-023-01776-z.