
Model performance can be further improved with the extra guidance apart from the one-hot ground truth. To achieve it, recently proposed recollection-based methods utilize the valuable information contained in the past training history and derive a “recollection” from it to provide data-driven prior to guide the training.
Recently, Dr Xi Li, Professor from College of Computer Science and Technology at Zhejiang University, and Adjunct Professor of Shanghai Institute for Advanced Study, Zhejiang University and colleagues proposed anovel recollection-based training framework, including multirecollection construction and EKD.
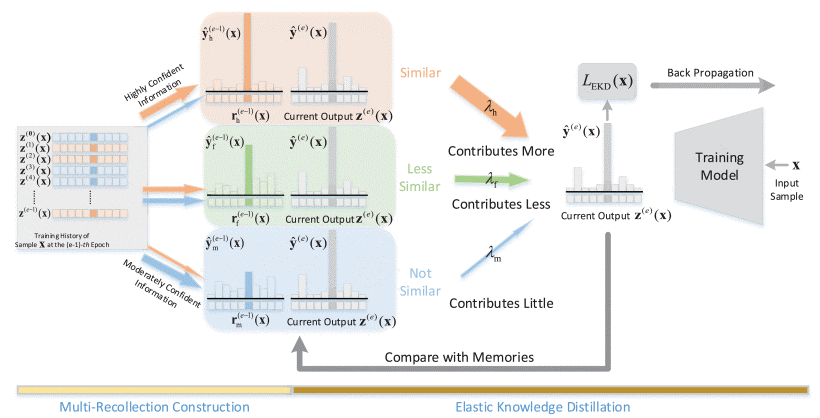
Figure 1. Overview of the method. Left: the authors take three recollections with different distributions as an example. Different recollections are from the same training history, but the contribution of each history records z(e) is different. Right: each recollection contributes differently during the training and the weight coefficient varies adaptively and dynamically during the training, according to the similarity of recollections and current output.
The authors focused on two fundamental aspects of the recollection-based method, i.e., recollection construction and recollection utilization. Recollections with diverse distribution are derived from the same training history according to certainty gain, and all of them can elastically collaborate together to guide the training procedure. Specifically, to meet the various demands of models with different capacities and at different training periods, they constructed a set of recollections with diverse distributions from the same training history. After that, all the recollections collaborated together to provide guidance, which was adaptive to different model capacities, as well as different training periods, according to the similarity-based elastic knowledge distillation (KD) algorithm. Without any external prior to guide the training, the above method achieved a significant performance gain and outperformed the methods of the same category, even as well as KD with well-trained teacher. Extensive experiments and further analysis were conducted to demonstrate the effectiveness of the method in providing suitable guidance adaptive to different model capacities, as well as different training periods.
The work was published as ‘Elastic Knowledge Distillation by Learning from Recollection’ in IEEE Transactions on Neural Networks and Learning Systems, and to access the full article, please refer to https://ieeexplore.ieee.org/document/9546048.